
تحلیل آماری رگرسیون پواسون
این آموزش توسط سایت کافه پروژه برای ارتقای سطح علمی دانشجویان و علاقه مندان به نرم افزار spss تنظیم شده و هدفش آشنایی با آزمون های موجود در این نرم افزار و نحوه انجام این آزمون ها و کمک به دانشجویان و پژوهشگران برای حل مسائل تحقیقی با استفاده از آزمون های این نرم افزار است لذا به جهت گستردگی مطالب در چندین قسمت درحال برگذاری هست.و در هر قسمت بطور جداگانه آموزش های لازم داده خواهد شد
تجزیه و تحلیل رگرسیون پواسون با استفاده از نرم افزار اس پی اس اس
بعد از آشنایی با رگرسیون پواسون و اوردن فرضیاتی در رابطه با این آزمون در ادامه با رگرسیون پواسون در اس پی اس اس آشنا می شویم
در ادامه قصد داریم آموزش نرم افزار spss و پروژه spss را به شما ارائه دهیم.لطفا تا پایان با ما همراه باشید و آموزش های ما را دنبال نمایید.
رگرسیون پواسون | نمونه های تجزیه و تحلیل داده ها از طریق نرم افزار اس پی اس اس
از رگرسیون پواسون برای مدل سازی متغیرهای قابل شمارش استفاده می شود.
لطفا توجه داشته باشید: هدف از این پژوهش نشان دادن روش استفاده از دستورات مختلف تجزیه و تحلیل داده ها است
پیشنهاد نرم افزار مشابه : برای انجام پروژه های تحلیل آماری نرم افزار دیگری وجود دارد که همانند spss کارایی بالایی دارد.انجام پروژه اکسپرت چویس محبوبیت زیادی در بین محققین و دانشجویان دارد و بسیاری از شرکتها از این نرم افزار برای کارهای آماری خود استفاده می کنند.
با دیگر خدمات سایت کافه پروژه آشنا شوید :
ادامه آموزش را دنبال نمایید…
مثال هایی از رگرسیون پواسون
مثال ۱. تعداد افراد کشته شده با لگد قاطر یا اسب در ارتش پروس در سال. ۱۸۰۰ داده ها را از ۲۰ جلد از یک کتاب جمع آوری کرد. این داده ها در ۲۰ سال از ۱۰ سپاه ارتش پروس در اواخر دهه ۱۸۰۰ جمع آوری شد.
مثال ۲. تعداد افرادی که در صف مقابل شما در فروشگاه مواد غذایی هستند. پیشبینیکنندهها ممکن است شامل تعداد لوازمی باشند که در حال حاضر با قیمت مناسب و تخفیف ویژه عرضه میشوند و اینکه آیا یک اتفاق ویژه (به عنوان مثال، یک روز تعطیل، یک رویداد ورزشی بزرگ) سه روز یا کمتر باقی مانده است.
مثال ۳. تعداد جوایز بدست آمده توسط دانش آموزان در یک دبیرستان. پیش بینی کننده تعداد جوایز بدست آمده شامل نوع برنامه ای است که دانش آموز در آن ثبت نام کرده است (به عنوان مثال، حرفه ای، عمومی یا دانشگاهی) و نمره امتحان نهایی آنها در درس ریاضی.
نکته: یک دیگر از خدماتی که توسط سایت کافه پروژه ارائه می شود کار ریوایز مقاله است. جهت ریوایز مقاله خود نیازمند آموزش کافه پروژه از ابتدا ملاحظه نمایید جهت مشاهده و آموزش های مرتبط با این پروژه لازم است کلمه آموزش پروژه ریوایز مقاله را در بخش جستجو وارد نمایید و اینتر بزنید.
تجزیه و تحلیل داده ها با استفاده از . رگرسیون پواسون
در زیر از دستور genlin برای برآورد مدل رگرسیون پواسون استفاده می کنیم. ما یک متغیر پیش بینی کننده پیوسته و یک متغیر پیش بینی کننده طبقه ای داریم. در قسمت genlin، ما متغیر پیشبینیکننده طبقهبندی خود را بعد از «by» و متغیر پیشبینی پیوسته خود را بعد از «with» انتخاب میکنیم. هر دو در مسیر مدل ظاهر می شوند. ما از گزینه covb=robust درمسیر معیار برای به دست آوردن اشتباهات استاندارد قوی برای برآورد پارامترها استفاده می کنیم در نهایت، از نرم افزار اس پی اس اس میخواهیم که آمار مناسب مدل، خلاصه اثرات مدل و برآورد پارامترها را تحلیل کند و بدست آورد

نکته : سایت فریلنسینگ کافه پروژه یکی از بزرگترین سایتهای پروژه تحلیل آماری در ایران است که از وجود صدها فریلنسر متخصص کارهای آماری بهره می برد.جهت سفارش پروژه ثبت نام نمایید و پروژه خود را ایجاد کنید
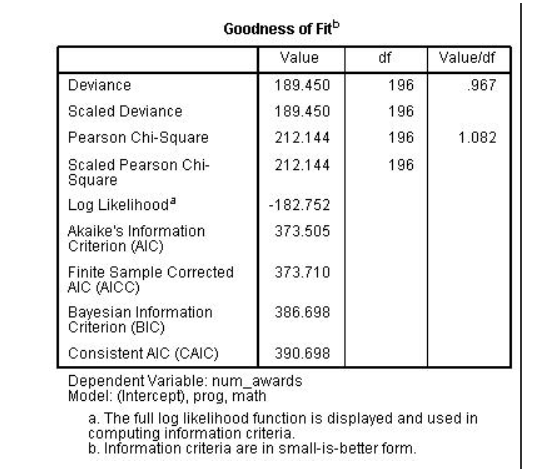
جدول نتایج
جدول خروجی رگرسیون پواسون با جدول Goodness of Fit شروع می شود. این آمارهای مختلفی را بدست می آورد که نشاندهنده مناسب بودن مدل است. برای ارزیابی برازش مدل، آزمون کای دو بدست می آید که برازش در خط اول این جدول ارائه شده است. ما انحراف (۱۸۹.۴۵) را به عنوان آزمون کای دو با درجات آزادی مدل (۱۹۶) ارزیابی می کنیم. این آزمون ضرایب مدل نیست بلکه آزمایشی از فرم مدل پواسون است: آیا فرم مدل پواسون با داده های ما مطابقت دارد؟ نتیجه میگیریم که مدل به خوبی برازش دارد زیرا آزمون مجذور کای خوب بودن برازش از نظر آماری معنیدار نیست (با ۱۹۶ درجه آزادی، ۲۰۴/۰ = p). اگر آزمون کای دو از نظر آماری معنی دار بود، نشان می داد که داده ها به خوبی با مدل مطابقت ندارند. در آن شرایط، ممکن است تلاش کنیم مشخص کنیم که آیا متغیرهای پیشبینی کننده حذف شده وجود دارد یا خیر، آیا فرضیه خطی بودن مدل ما برقرار است و/یا آیا مشکلی از نظر پراکندگی بیشتر از حد وجود دارد.
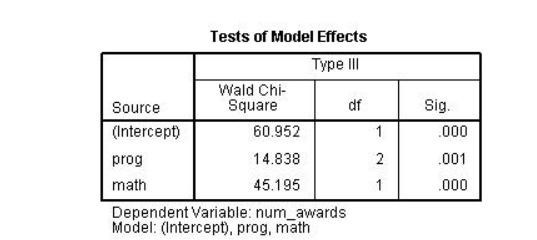
در ادامه آزمون امیبیوس را می بینیم. این آزمونی است که تمام ضرایب برآورد شده برابر با صفر هستند – آزمونی از مدل به عنوان یک کل. از سطح معنی داری یا sig می توان دریافت که مدل از نظر آماری معنی دار است.
بعدآزمون های جلوه های مدل است. این آزمون هر یک از متغیرهای مدل را با درجات آزادی مناسب ارزیابی می کند. متغیر پروگ دارای سه بعد است. بنابراین، در مدل به عنوان دو متغیر شاخص با یک درجه آزادی نمایان می شود. برای ارزیابی اهمیت پراگ به عنوان یک متغیر، باید این دو متغیر ساختگی را با هم در یک آزمون کای دوکه دارای درجه آزادی هستند آزمایش کنیم. این نشان میدهد که متغیر پراگ یک پیشبینیکننده آماری معنادار برای متغیر بدون پاداش است. متغیر پیشبینیکننده پیوسته به یک درجه آزادی در مدل نیاز دارد، بنابراین آزمونی که در اینجا عرضه میشود معادل آن در جدول خروجی تخمین پارامتر است.
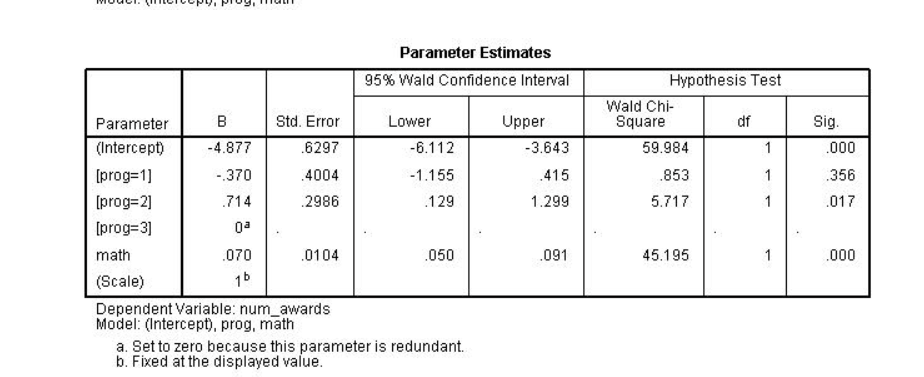
در مرحله بعد، برآورد پارامترها را می بینیم. که این جدول شامل ضرایب رگرسیون برای هر یک از متغیرها به همراه خطاهای استاندارد قوی، مقدارهای سطح معنی داری و فاصله اطمینان ۹۵ درصد برای ضرایب است. ضریب عددی ۰.۰۷ است. این بدان معنی است که افزایش مورد انتظار در متغیرهای قابل شمارش برای افزایش یک واحدی از نظر عددی ۰.۰۷ است. متغیر نشانگر [prog=1] تفاوت مورد انتظار در متغیر قابل شمارش بین گروه ۱ و گروه مرجع [prog=3] است. در مقایسه با بغد سوم متغیر پراگ ، تعداد نتایج مورد انتظار برای بعد اول متغیر پراگ حدود ۰.۳۷ کاهش می یابد. متغیر نشانگر [prog=2] تفاوت مورد انتظار درمتغیر قابل شمارش بین گروه دوم و گروه مرجع است. در مقایسه با بعد سوم متغیر پراگ ، تعداد مشاهدات مورد انتظار برای سطح دوم متغیر پراگ حدود ۰.۷۱ افزایش می یابد. ما از جدول خروجی Tests of Model Effects دیدیم که متغیر پراگ ، به طور کلی، از نظر آماری معنادار است.
مواردی که باید در نظر بگیریم
هنگامی که به نظر می رسد مشکل پراکندگی وجود دارد، در ابتدا باید بررسی کنیم که آیا مدل ما به درستی تعیین شده است، مانند متغیرهای حذف شده و مدل های عملکردی. به عنوان مثال، اگر متغیر پیشبینیکننده پراگ را در مثال بالا حذف کنیم، به نظر میرسد مدل ما با پراکندگی بیشتر از حد مشکل دارد. به عبارت دیگر، یک مدل و فرم اشتباه مشخص میتواند نشانهای مانند مشکل پراکندگی بیشتر از حد را نشان دهد.
با این فرضیه که مدل به درستی تعیین شده است، ممکن است بخواهید پراکندگی بیشتر از حد را آزمون کنید. چندین آزمون مانند آزمون نسبت احتمال پارامتر آلفای بیش پراکندگی با اجرای مدل رگرسیون مشابه با استفاده از توزیع دوبعدی منفی (توزیع = negbin) وجود دارد.
یکی از دلایل رایج پراکندگی بیشتر از حد صفرهای اضافی است که به نوبه خود توسط یک مرحله ایجاد داده اضافی بوجود می آید . در این شرایط باید مدل تورم صفر را در نظر گرفت.
پیشنهاد لینک : اگر دنبال کارهای تحقیقاتی در این حوزه هستید و کار نرم افزاری به کارتان نمی آید میتوانید به صفحه انجام تحقیق سایت کافه پروژه مراجعه نمایید
اگر روش تولید داده اجازه هیچ 0s (مانند تعداد روزهای سپری شده در بیمارستان) را نمی دهد، در این صورت احتمال دارد مدل برش صفر مناسب تر باشد.
متغیر نتیجه در رگرسیون پواسون نمی تواند دارای اعداد منفی باشد.
رگرسیون پواسون از طریق برآورد حداکثر درستنمایی تخمین زده می شود و. معمولاً به میزان نمونه بزرگی نیاز دارد.و تعداد نمونه و حجم نمونه خیلی بالاست
در ادامه قصد داریم آموزش نرم افزار spss و انجام پروژه با نرم افزار spss را به شما ارائه دهیم.لطفا تا پایان با ما همراه باشید و آموزش های ما را دنبال نمایید.
برای مشاهده همه مطالب آموزشی در این رابطه کلمه آموزش spss را در بخش جستجوی سایت تایپ کرده و اینتر بزنید.
نحوه سفارش پروژه در سایت کافه پروژه :
اگر پروژه ای دارید که میخواهید آن را برون سپاری کنید کافی است در سایت کافه پروژه ثبت نام کنید و پروژه خود را ثبت نمایید.پروژه شما هر چه که باشد حتما مجری برای آن وجود دارد.جهت ثبت نام و ثبت سفارش پروژه خود برروی دکمه زیر کلیک نمایید.

){kind=link}
بدون دیدگاه