
تحلیل آماری رگرسیون پواسون
این آموزش توسط سایت کافه پروژه برای ارتقای سطح علمی دانشجویان و علاقه مندان به نرم افزار spss تنظیم شده و هدفش آشنایی با آزمون های موجود در این نرم افزار و نحوه انجام این آزمون ها و کمک به دانشجویان و پژوهشگران برای حل مسائل تحقیقی با استفاده از آزمون های این نرم افزار است لذا به جهت گستردگی مطالب در چندین قسمت درحال برگذاری هست.و در هر قسمت بطور جداگانه آموزش های لازم داده خواهد شد
تجزیه و تحلیل رگرسیون پواسون با استفاده از نرم افزار اس پی اس اس
بعد از آشنایی با رگرسیون پواسون و اوردن فرضیاتی در رابطه با این آزمون در ادامه با رگرسیون پواسون در اس پی اس اس آشنا می شویم
در ادامه قصد داریم آموزش نرم افزار spss و پروژه spss را به شما ارائه دهیم.لطفا تا پایان با ما همراه باشید و آموزش های ما را دنبال نمایید.
تفسیر و گزارش نتایج تحلیل رگرسیون پواسون
آمار اس پی اس اس تعداد زیادی جدول نتایج برای تحلیل رگرسیون پواسون بوجود می آورد. در این قسمت، هشت جدول اصلی مورد نیاز برای درک نتایج خود از آزمون رگرسیون پواسون را به شما نشان می دهیم، با این فرضیه که هیچ فرضییه ای از بین نرفته است.
داده های طرح و متغیر
اولین جدول در خروجی جدول داده های طرح است (مانند شکل زیر). این تأیید می کند که متغیر ملاک “تعداد انتشارات”، توزیع احتمال “پواسون” و وابسته پیوند لگاریتم طبیعی است (به عنوان مثال، “Log”). اگر رگرسیون پواسون را برروی داده های خود به اجرا در می آورید، اسم متغیر وابسته فرق خواهد کرد، اما توزیع احتمال و وابسته پیوند برابر خواهد بود.

پیشنهاد نرم افزار مشابه : برای انجام پروژه های تحلیل آماری نرم افزار دیگری وجود دارد که همانند spss کارایی بالایی دارد.انجام پروژه eviews محبوبیت زیادی در بین محققین و دانشجویان دارد و بسیاری از شرکتها از این نرم افزار برای کارهای آماری خود استفاده می کنند.
با دیگر خدمات سایت کافه پروژه آشنا شوید :
انجام پروژه کارشناسی و کارشناسی ارشد
ادامه آموزش را دنبال نمایید…
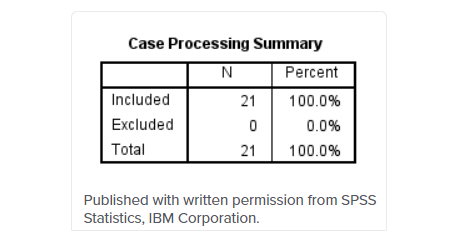
جدول دوم، خلاصه نتایج پردازش شده ، به شما نشان می دهد که چند مورد (به عنوان مثال، موضوعات) در تجزیه و تحلیل شما را شامل شده (ردیف “شامل”) و چند مورد شامل نشده (ردیف “متمایز شده”) و همچنین درصد موارد شامل شده است. هر دو. میتوانید ردیف « را بهعنوان مواردی (بهعنوان مثال، موضوعات) که یک یا چند موارد گمشده دارند، در نظر بگیرید. همانطور که در زیر می بینید، ۲۱ موضوع و مورد در این تجزیه و تحلیل وجود داشت که هیچ موردی حذف نشد (یعنی موارد گمشده ای وجود نداشت)
نکته: یک دیگر از خدماتی که توسط سایت کافه پروژه ارائه می شود کار ریوایز مقاله است. جهت ریوایز مقاله خود نیازمند آموزش کافه پروژه از ابتدا ملاحظه نمایید جهت مشاهده و آموزش های مرتبط با این پروژه لازم است کلمه آموزش پروژه ریوایز مقاله را در بخش جستجو وارد نمایید و اینتر بزنید.
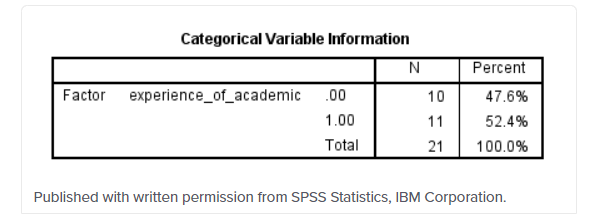
جدول اطلاعات متغیر طبقهای،
تعداد و درصد متغیرها (به عنوان مثال، موضوعات) را در هر دسته از هر متغیربا طبقهبندی مستقل در تحلیل شما را نمایان می سازد. در این تحلیل، تنها یک متغیر مستقل طبقه ای (همچنین به عنوان “عامل” شناخته می شود) وجود دارد که تجربهی آکادمیکی بود. می بینید که گروه ها از نظر تعداد در دو گروه نسبتاً متعادل و برابرهستند (یعنی ۱۰ در مقابل ۱۱). اندازه های بسیار نامتعادل و نابرابر گروه می تواند در متناسب بودن مدل مشکلاتی ایجاد کند، اما می بینیم که در اینجا مشکلی وجود ندارد.
جدول داده های متغیر پیوسته می تواند یک بررسی مقدماتی از اطلاعات برای هر گونه مشکل ارائه دهد، اما نسبت به سایر آمارهای توصیفی که می توانید قبل از اجرای رگرسیون پواسون به طور جداگانه اجرا کنید، مناسب تر است. بهترین چیزی که می توانید از این جدول کسب کنید این است که متوجه شوید که آیا ممکن است در تحلیل شما پراکندگی بیشتر از حد وجود داشته باشد (به عنوان مثال، فرضیه شماره ۵ رگرسیون پواسون). می توانید این کار را با در نظر گرفتن نسبت واریانس (مربع ستون “انحراف استاندارد”) به میانگین (ستون “میانگین”) برای متغیر وابسته انجام دهید. در زیر می توانید این اعداد را ملاحظه کنید:

میانگین ۲.۲۹ و انحراف استاندارد ۲.۸۱ (۱.۶۷۷۵۸۲) است که نسبت ۲.۸۱ ÷ ۲.۲۹ = 1.۲۳ است. توزیع پواسون نسبت ۱ را فرض می کند (یعنی میانگین و انحراف استاندارد برابر هستند). بنابراین، میتوانیم ببینیم که قبل از اینکه متغیرهای توضیح دهنده را اضافه کنیم، به میزان کمی بیشپراکندگی وجود دارد. با این حال، زمانی که همه متغیرهای مستقل به رگرسیون پواسون اضافه شده اند، باید این فرضیه را بررسی کنیم.
پیشنهاد لینک : اگر دنبال کارهای تحقیقاتی در این حوزه هستید و کار نرم افزاری به کارتان نمی آید میتوانید به صفحه پروژه تحقیق سایت کافه پروژه مراجعه نمایید
مشخص کردن میزان متناسب بودن مدل
جدول متناسب بودن مدل معیارهای زیادی را ارائه می کند که می توان از آنها برای ارزیابی میزان متناسب بودن مدل استفاده کرد. با این حال، ما روی مقدار ستون “درجه آزادی متغیر” برای ردیف “ضریب همبستگی پیرسون” تمرکز می کنیم که در این مثال ۱.۱۰۸ است، همانطور که در زیر نشان داده شده است:
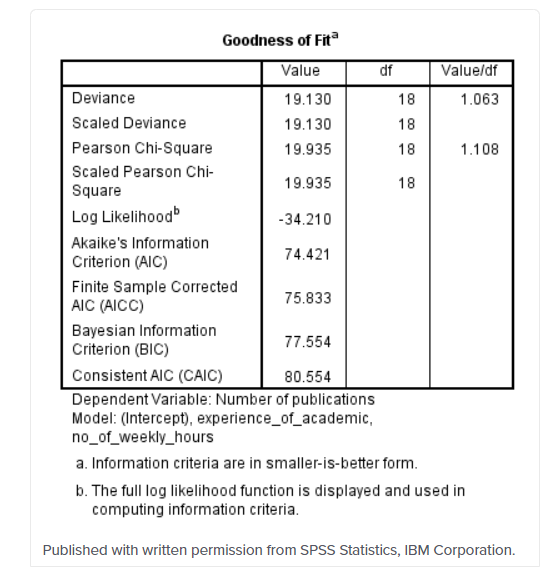
مقدار یک نشانه پراکندگی همسان و همانند است در حالی که اعداد بیشتر از ۱ نشان دهنده پراکندگی بیشتر از حد واعداد زیر یک نشان دهنده عدم پراکندگی است. رایج ترین نوع از بین بردن فرضیه همسان بودن پراکندگی بیشتر از میزان متناسب است. با چنین میزان نمونه کوچکی در این مثال، مقدار ۱.۱۰۸ بعید است که بطور جدی این فرضیه را نقض می کند.
جدول آزمون امیبیوم جایی بین این قسمت و قسمت بعدی قرار می گیرد. این یک آزمون نسبت احتمال است که نشان می دهد آیا همه متغیرهای مستقل روی هم رفته مدل ما را نسبت به مدل فقط رهگیری بهبود می بخشند (یعنی بدون هیچ متغیر مستقل اضافه شده). با داشتن همه متغیرهای مستقل در مدل مثال ما، مقدار سطح معناداری برابر با ۰.۰۰۶ (یعنی p = 0.006) داریم که نشان دهنده یک مدل کلی آماری معنی دار است، همانطور که در زیر در “سطح معناداری” نشان داده شده است. ستون:

اکنون که میدانید اضافه کردن همه متغیرهای مستقل در یک مدل از نظر آماری معنیداری ایجاد میکند، میخواهید بدانید که کدام متغیرهای مستقل ویژه از نظر آماری معنادار هستند. در قسمت بعدی به این موضوع می پردازیم
اثرات مدل و معناداری آماری متغیرهای مستقل
جدول اثرات مدل (همانطور که در زیر نشان داده شده است) اهمیت آماری هر یک از متغیرهای مستقل را در “سطح معناداری” نشان می دهد. ستون:
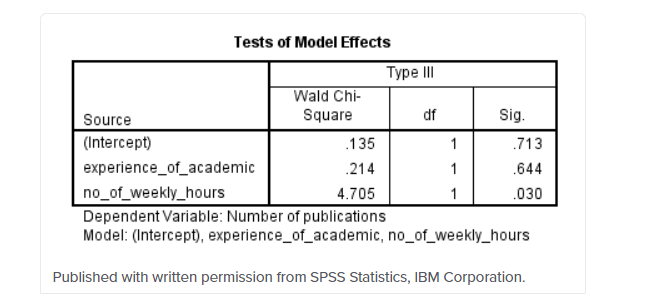
معمولاً هیچ علاقه ای به مدل رهگیری وجود ندارد. با این حال، میتوان دید که تجربه دانشگاهیان از نظر آماری معنیدار نبود (۶۴۴/۰=p)، اما میزان ساعات کار در هفته از نظر آماری معنیدار بود (۰۳۰/۰=p). این جدول بیشتر برای متغیرهای مستقل طبقهبندی شده مناسب است، زیرا تنها جدولی است که بر خلاف جدول برآورد پارامترها، همانطور که در زیر نشان داده شده است، تأثیر کلی یک متغیر طبقهبندی شده را در نظر میگیرد
نکته : سایت فریلنسینگ کافه پروژه یکی از بزرگترین سایتهای پروژه تحلیل آماری در ایران است که از وجود صدها فریلنسر متخصص کارهای آماری بهره می برد.جهت سفارش پروژه ثبت نام نمایید و پروژه خود را ایجاد کنید
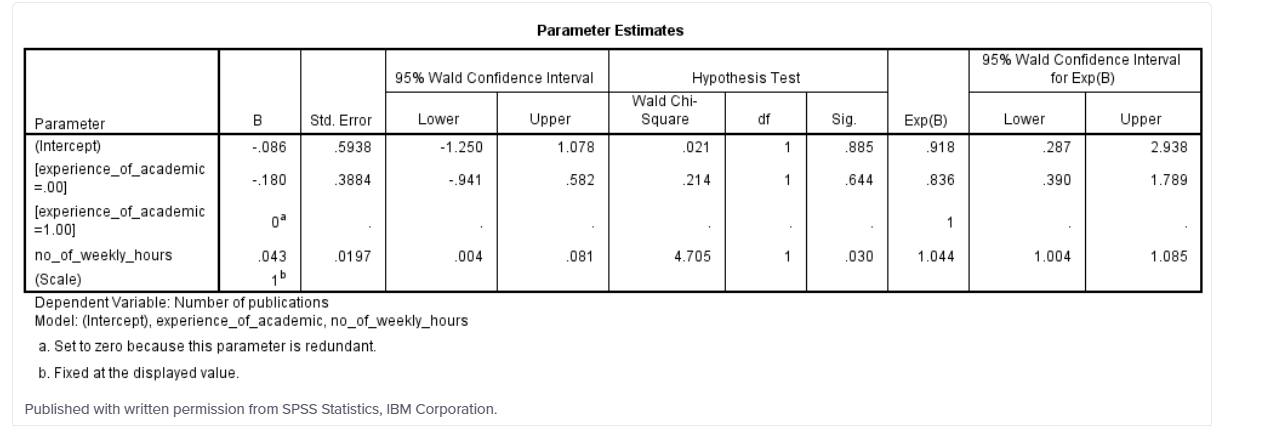
این جدول هم برآورد های ضرایب (ستون “B”) رگرسیون پواسون و هم مقدارهای توانمندی ضرایب (ستون “Exp(B)”) را نمایش می دهد. معمولاً این دومی ها آموزنده تر هستند. این مقدارهای نشان داده شده را می توان به بیش از یک روش تحلیل کرد و ما در این آموزش یک راه را به شما نشان خواهیم داد. به عنوان مثال، میزان ساعات کار در هفته را در نظر بگیرید (یعنی ردیف ” میزان ساعات کار در هفته “). مقدار نمایی ۱.۰۴۴ است. این بدان معناست که تعداد انتشارات (یعنی تعداد متغیر وابسته) برای هر ساعت کار اضافی در هفته ۱.۰۴۴ برابر بیشتر بوده است راه دیگری برای بیان این موضوع این است که به ازای هر ساعت کار اضافی در هفته، ۴.۴ درصد افزایش در میزان انتشارات وجود دارد. تفسیر مشابهی را نیز می توان برای متغیر طبقه بندی شده انجام داد
همه این موارد را کنار هم بگذار
می توانید نتایج میزان ساعات کار در هفته را به صورت زیر بنویسید:
یک رگرسیون پواسون برای پیشبینی مقدار انتشاراتی که یک دانشگاه در ۱۲ ماه گذشته منتشر میکند بر اساس تجربه دانشگاهی و مقدار ساعتهایی که یک دانشگاه در هفته صرف کار بر روی پژوهش میکند، اجرا شد. به ازای هر ساعت کار اضافی در هفته بر روی یک پژوهش، ۱.۰۴۴ (۹۵% فاصله اطمینان (CI)، ۱.۰۰۴ تا ۱.۰۸۵) برابر بیشتر انتشارات منتشر شد که یک نتیجه آماری معنی دار، ۰.۰۳۰ = p. است
در ادامه قصد داریم آموزش نرم افزار spss و انجام پروژه با نرم افزار spss را به شما ارائه دهیم.لطفا تا پایان با ما همراه باشید و آموزش های ما را دنبال نمایید.
برای مشاهده همه مطالب آموزشی در این رابطه کلمه آموزش spss را در بخش جستجوی سایت تایپ کرده و اینتر بزنید.
نحوه سفارش پروژه در سایت کافه پروژه :
اگر پروژه ای دارید که میخواهید آن را برون سپاری کنید کافی است در سایت کافه پروژه ثبت نام کنید و پروژه خود را ثبت نمایید.پروژه شما هر چه که باشد حتما مجری برای آن وجود دارد.جهت ثبت نام و ثبت سفارش پروژه خود برروی دکمه زیر کلیک نمایید.

){kind=link}
بدون دیدگاه