
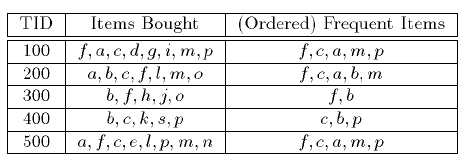
الگوی الگوریتم های شرطی داده کاوی
الگوی شرطی:
برای روشن مفهوم فوق (الگوی شرطی) شکل را در نظر بگیرید.آیتم p را در نظر بگیرید.مطابق شکل شاخه های پیشوند های p در درخت عبارتند از <f:4,c:3,a:3,m:2> و زیر شاخه. <c:1,b:1> به این معنی که مجموعه آیتم های پیشوندی در پایگاه داده عبارتند از <c:1,b:1>,<f:2,c:2,a:2,m:2> که به این دو الگوی های شرطی میگوییم.
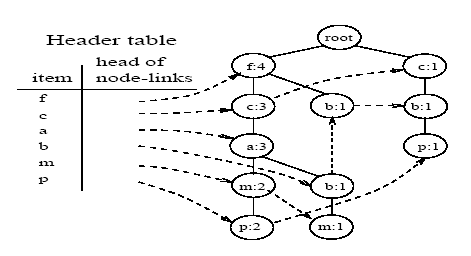
Fp-tree شرطی :
در صورتیکه با الگوهای شرطی, از نو یک fp-tree درست کنیم و نود مربوط به آیتم هایی که تعداد تکرار کمتر از دارند را حذف کنیم, درخت حاصل fp-tree شرطی نامیده میشود.و به صورت(fp-tree|p) نمایش داده می شود ) که p آیتم مربوطه است)
(fp-tree|m) در شکل زیر مشخص است.
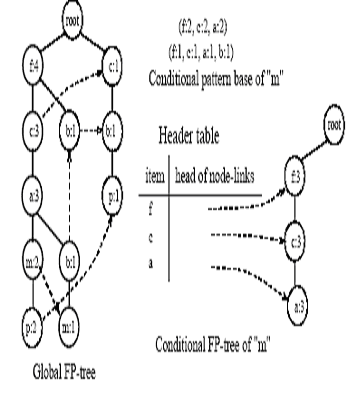
الگوریتم ایجاد مجموعه آیتم های بزرگ بوسیله درخت fp-tree
روش کار به این صورت است که ابتدا به ازای هر آیتم بزرگ مثل {a} کارهای زیر را تکرار می کنیم :
۱- temp =λ
۲-اگر , aÈtemp را به مجموعه آیتم های بزرگ اضافه کن
T1=(fp-tree|a) را در درخت ایجاد میکنیم و (temp=a).
دوباره درداخل این fp-treeجدید(T1) به ازای هرآیتم بزرگ دراین fp-treeمثل a’ در صورتیکه (تکراردردرخت T1)}È temp, {a’ به مجموعه آیتم های بزرگ اضافه می شودو دوباره همین کار را برای ( T2 =(T1|a’ حاصل از درخت T1 تکرار می کنیم.
(مقدار temp قبل از فراخوانی تابع (T1|a’) برابرست با : temp=a’ È temp’)
الگوریتم برداری
برای هر آیتم یک بردار مشخصات (ویژگی) فشرده به همراه یک رکورد ویژگی ساخته میشود. این ساختار فقط یکبار در هنگامی که پایگاه داده برای اولین بار خوانده میشود، ساخته میشود. سپس برای پوشش محاسبه هر مجموعه آیتم, از بردارهای فوق( به جای پایگاه داده ) استفاده میشود.
لذا دسترسی مجدد به پایگاه داده اولیه نیازی نیست و محاسبات نیز بسیار سریعتر از الگوریتمهای قبل میباشد.
الگوریتم ارائه شده:
ایدهی این روش، استخراج ویژگیهای آیتمهای مشخص شده۱ و ذخیره آنها در یک بردار فشرده است. پس از اینکه بردار فشرده این آیتمها ساخته شود همه محاسبات برای مشخص شدن پوشش (تعداد تکرار در پایگاه داده) هر مجموعه آیتم از طریق عملیا ت AND بین بردارها صورت میگیرد بجای دسترسی مجدد به پایگاه داده.
(بردار فشردهی یک آیتم مشخص میکند که این آیتم در کدام تراکنشها رخ داده است)
در الگوریتم(Tseng,2000) دو پایگاه داده داریم بنامهای Support DB و feature DB:
feature DB : بردارهای مربوط به آیتمها را مشخص میکند. (هرخانه آن بردار مربوط به یک آیتم است)
Support DB: پوشش هر آیتم را در بر دارد.
هنگامی که کاربر یک تقاضا مبتنی بر کشف قوانین وابستگی بین آیتمهای IT (که ) با حداقل پوشش minsupp و حداقل درجه اطمینان minconf می دهد، در این روش ابتدا چک میکنیم ببینیم , آیا feature DB , Support DB وجود دارند یا نه در صورتیکه وجود نداشته باشند
آن ها را میسازد. ساخت feature DB , Support DB احتیاج به یک دور خواندن کل پایگاه داده دارد.
در طول خواندن پایگاه داده، Feature DB ، Support DB برای آیتمهای مشخص شده توسط کاربر نیز ساخته میشود. پس از اینکه Feature DB Support DB, ساخته شدند در دیسک
می گیرند.
لذا , را نیز با دسترسی مستقیم به Support DB مشخص کنیم , بجای خواندن کل پایگاه داده.
پس از مشخص شدن ، بردار هر مجموعه آیتم مورد نیاز نیز با عملیات AND به سرعت انجام میشود.
۱) IF (SupportDB is empty)
Scan the database to build SupportDB and determine , and build Feature DB for interested items;
ELSE
Retrieve SupportDB and determine and build FeatureDB for non-existent items;
۲) k=2
۳) Generate candidate large itemsetfrom;
۴) IF is not empty
Optain the count for each itemset in by bitwise AND operators on the items’ feature vectors and get;
go to step 3;
۵) Answer= union of all;
مرحله ساخت بردار برای آیتم d به صورت زیر است:
بردار یک بردار است به طول تعداد تراکنشهای پایگاه داده. در صورتیکه آیتم d در یک تراکنش با شناسهی j باشددر غیر اینصورت . (فرض بر این است که شناسهها در پایگاه داده از ۱ تا۱- nطول پایگاه داده” است) مثلاً اگرآیتم a در یک پایگاه دادهی ۱۰ عضوی فقط در رکوردهای ۱۰,۵,۴ رخ دهد, داریم:
| ۱ | ۲ | ۳ | ۴ | ۵ | ۶ | ۷ | ۸ | ۹ | ۱۰ |
| ۰ | ۰ | ۰ | ۱ | ۱ | ۰ | ۰ | ۰ | ۰ | ۱ |
به این ترتیب با داشتن بردار هر آیتم برای مشخص کردن بردار هر مجموعه آیتم مثل داریم :
بدیهی است که تعداد ۱ ها در بردار هر مجموعه آیتم برابر پوشش آن مجموعه آیتم است.
به این ترتیب تمام مجموعه آیتمهای بزرگ تولید میشوند.
واضح است که در یک بردار مقادیر زیادی صفر وجود دارد که فضای زیادی را اشغال میکنند. برای رفع این مشکل میتوان در صورتیکه چندین (بیشتر از ۸) ۰ پشت سر هم وجود داشت تعداد آنها را بشماریم و در یک index ِ شمارنده ذخیره کنیم. با ذخیره بردار هر آیتم دسترسی به پایگاه داده به حداقل میرسد.
یک راه حل دیگر اینست که برای هر آیتم فقط شماره رکوردهایی را که آیتم در آنها رخ داده را ذخیره کنیم یعنی به عنوان مثال اگر آیتم a در رکوردهای شماره ۲۲۰,۲۰۱,۱۰۰ رخ داده بردار آن به شکل زیر است:
در اینصورت برای هر مجموعه آیتم X بردار به شکل زیر است:
ساخت و هرس کردن مجموعه آیتمهای کاندید بزرگ از همانند الگوریتم Aprioriاست با این تفاوت که برای شمارش پوشش هر مجموعه آیتم این کار از طریق عملیات AND یا اشتراک انجام میدهیم.
و تنها برای محاسبهی بردارهای هر آیتم, پایگاه داده را در ابتدای کار یک دور میزنیم.
یک الگوریتم جدید برای پایگاه داده های پویا
پویایی پایگاه داده را از دو جنبه می توان بررسی کرد :
- هنگامی که داده ها تغییر کنند (یک رکورد تغییر کند) یا داده ها از پایگاه داده حذف شوند .
- هنگامی که داده ای ( رکورد جدید ) به پایگاه داده اضافه شود .
داده کاوی که با نوع اول از پویایی پایگاه داده تطابق دارد را داده کاوی کاهشی و داده کاوی که با نوع دوم پویایی تطابق دارد را داده کاوی افزایشی می نامیم.
الگوریتم Zhang &Etal,2003) ) از نوع الگوریتم کاهشی است . یعنی ورودی را بررسی میکنیم که میخواهیم داده کاوی را در یک پایگاه داده که داده هایش دائما حذف شده و یا تغییر کرده اند انجام میدهیم و قاعدتا انتظار داریم که الگوریتم در فواصل مختلف زمانی که پایگاه داده مورد تغییر (یا حذف) قرار می گیرد با بکارگیری الگوهای حاصل از داده کاوی قبلی از هزینه زمانی خوبی برخوردار باشد .
متاسفانه تحقیقی در مورد کشف قوانین وابستگی هنگامی که داده ها از پایگاه داده حذف می شوند صورت نگرفته است . در حالیکه حذف ،یکی از عملیات اساسی در پایگاه داده است .
لذا کاربر باید دوباره الگوریتم داده کاوی را برای پایگاه داده جدید با تولید تمام الگوها از اول بکار گیرد که این کار بسیار پر هزینه است .
–۱آیتم هایی که توسط کاربر مشخص می شود.
از شما دوستان عزیز که این مطلب آموزشی را دنبال نموده اید تشکر می کنیم و شما را دعوت میکنیم که برای فراگیری داده کاوی مطالب ما را دنبال کنید.این مطالب برای افزایش دانش شما در سایت قرار داده شده و کمک زیادی در یادگیری شما در انجام پروژه داده کاوی خواهد نمود.
فریلنسر هستم و مهارت انجام پروژه ای را دارم!
اگر شما فریلنسر هستید و توانایی انجام پروژه ای را در یک رشته یا حوزه ای خاص دارید برای فعالیت در سایت کافه پروژه و کسب درآمد می توانید در سایت ثبت نام کنید و پروژه هایی با مهارت انتخاب خود را مشاهده کنید.جهت ثبت نام و ثبت رزومه خود در سایت از طریق دکمه پایین صفحه در سایت عضو شوید:
نحوه سفارش پروژه در سایت کافه پروژه :
اگر پروژه ای دارید که میخواهید آن را برون سپاری کنید کافی است در سایت کافه پروژه ثبت نام کنید و پروژه خود را ثبت نمایید.پروژه شما هر چه که باشد حتما مجری برای آن وجود دارد.جهت ثبت نام و ثبت سفارش پروژه خود برروی دکمه زیر کلیک نمایید.



{kind=link}
بدون دیدگاه