
مقدمه
رگرسیون خطی مرحله بعدی بعد از همبستگی است. زمانی استفاده می شود که بخواهیم مقدار یک متغیر را بر اساس مقدار متغیر دیگری پیش بینی کنیم. متغیری که می خواهیم پیش بینی کنیم، متغیر وابسته (یا گاهی اوقات، متغیر نتیجه) نامیده می شود. متغیری که برای پیشبینی مقدار متغیر دیگر استفاده میکنیم، متغیر مستقل (یا گاهی اوقات، متغیر پیشبینیکننده) نامیده میشود. به عنوان مثال، می توانید از رگرسیون خطی برای درک اینکه آیا طلاق بر اساس تحصیلات طرفین قابل پیش بینی است یا خیر، استفاده کنید. آیا می توان مصرف تریاک را بر اساس مدت زمان مصرف تریاک پیش بینی کرد. و غیره اگر به جای یک متغیر، دو یا چند متغیر مستقل دارید، باید از رگرسیون چندگانه استفاده کنید.
این راهنمای «شروع سریع» به شما نحوه انجام رگرسیون خطی با استفاده از نرم افزار اس پی اس اس و همچنین تفسیر و گزارش نتایج این آزمون را نشان می دهد. با این حال، قبل از اینکه شما را با این روش آشنا کنیم، باید فرضیه های مختلفی را که داده های شما باید رعایت کنند تا رگرسیون خطی به شما یک نتیجه معتبر بدهد، بدانید. در ادامه به این فرضیات می پردازیم.
آمار SPSS
فرضیه ها
هنگامی که تصمیم می گیرید داده های خود را با استفاده از رگرسیون خطی تجزیه و تحلیل کنید، بخشی از فرآیند شامل بررسی می شود تا مطمئن شوید که داده هایی که می خواهید تجزیه و تحلیل کنید واقعاً می توانند با استفاده از رگرسیون خطی تجزیه و تحلیل شوند. شما باید این کار را انجام دهید زیرا تنها زمانی استفاده از رگرسیون خطی مناسب است که دادههای شما از هفت فرضیه لازم برای رگرسیون خطی عبور کند تا نتیجه معتبری به شما بدهد. در عمل، بررسی این هفت فرضیه فقط کمی زمان بیشتری به تجزیه و تحلیل شما اضافه می کندو از شما میخواهد هنگام انجام تجزیه و تحلیل، روی چند دکمه دیگر در آمار SPSS کلیک کنید، و همچنین کمی بیشتر در مورد دادههای خود فکر کنید، و اینطوری انجام می شود و انجام آن دشوار نیست
نکته:جهت انجام پروژه spss خود نیازمند آن هستید که آموزش کافه پروژه را از ابتدا ملاحظه نمایید لذا جهت مشاهده و آموزش های مرتبط با این نرم افزار لازم است کلمه آموزشspss را در بخش جستجو وارد نمایید و اینتر بزنید
قبل از اینکه شما را با این هفت فرضیه آشنا کنیم، تعجب نکنید اگر هنگام تجزیه و تحلیل داده های خود با استفاده از آمار SPSS، یک یا چند مورد از این فرضیات از بین رفت (یعنی انجام نشد). زمانی که با دادههای دنیای واقعی کار میکنید، به جای نمونههای کتاب درسی، که اغلب به شما نشان میدهند چگونه رگرسیون خطی را زمانی که همه چیز خوب پیش میرود، به شما نشان میدهد، غیرواقعی نیست! با این حال، نگران نباشید. حتی زمانی که داده های شما برخی از فرضیه ها را با شکست مواجه می کند، اغلب راه حلی برای غلبه بر آن وجود دارد. ابتدا، بیایید به این هفت فرضیه نگاهی بیندازیم:
فرضیه شماره ۱: متغیر وابسته شما باید در سطح پیوسته اندازه گیری شود (به عنوان مثال، متغیر بازه یا نسبت است). نمونه هایی از متغیرهای پیوسته عبارتند از: زمان تجدید نظر (اندازه گیری شده بر حسب ساعت)، هوش (اندازه گیری شده با استفاده از نمره IQ)، عملکرد امتحان (اندازه گیری از ۰ تا ۱۰۰)، وزن (اندازه گیری شده بر حسب کیلوگرم)، و غیره. میتوانید در مقاله ما: انواع متغیر، درباره متغیرهای بازه و نسبت اطلاعات بیشتری کسب کنید.
فرضیه شماره ۲: متغیر مستقل شما نیز باید در سطح پیوسته اندازه گیری شود (یعنی متغیر بازه یا نسبت است). برای نمونههایی از متغیرهای پیوسته به گلوله بالا مراجعه کنید.
فرضیه شماره ۳: باید یک رابطه خطی بین دو متغیر وجود داشته باشد. در حالی که روشهای مختلفی برای بررسی وجود رابطه خطی بین دو متغیر شما وجود دارد، پیشنهاد میکنیم با استفاده از آمار SPSS یک Scatterplot ایجاد کنید که در آن میتوانید متغیر وابسته را در مقابل متغیر مستقل خود رسم کنید و سپس به صورت بصری نمودار پراکندگی را برای بررسی خطی بودن بررسی کنید. نمودار پراکندگی شما ممکن است چیزی شبیه به یکی از موارد زیر باشد:
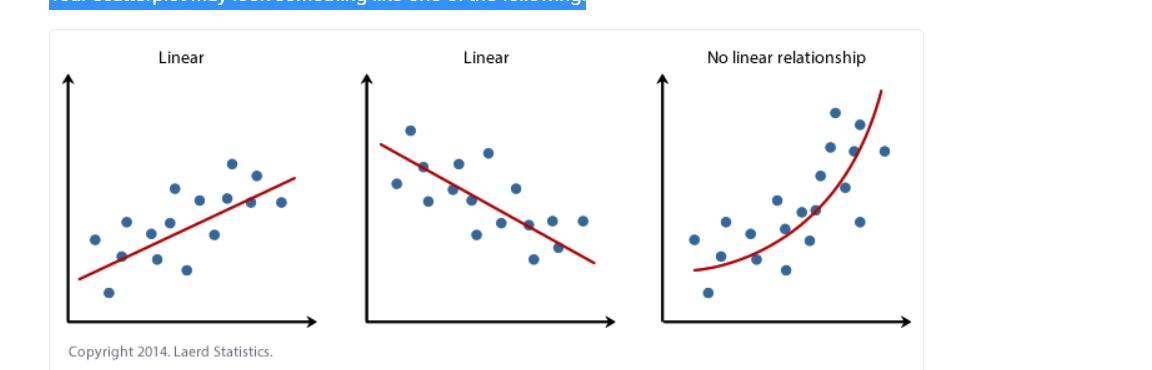
اگر رابطه نمایش داده شده در نمودار پراکندگی شما خطی نیست، باید یک تحلیل رگرسیون غیر خطی انجام دهید، یک رگرسیون چند جمله ای انجام دهید یا داده های خود را “تبدیل” کنید، که می توانید با استفاده از آمار SPSS انجام دهید. در راهنماهای پیشرفتهمان، ما به شما نشان میدهیم که چگونه: (الف) یک نمودار پراکنده برای بررسی خطی بودن هنگام انجام رگرسیون خطی با استفاده از آمار SPSS ایجاد کنید. (ب) نتایج مختلف پراکندگی را تفسیر کنید. و (ج) اگر رابطه خطی بین دو متغیر شما وجود نداشته باشد، داده های خود را با استفاده از آمار SPSS تغییر دهید.
فرضیه شماره ۴: نباید نقاط پرت قابل توجهی وجود داشته باشد. نقطه پرت یک نقطه داده مشاهده شده است که دارای یک مقدار متغیر وابسته است که با مقدار پیش بینی شده توسط معادله رگرسیون بسیار متفاوت است. به این ترتیب، نقطه پرت نقطه ای در یک نمودار پراکنده خواهد بود که (به صورت عمودی) از خط رگرسیون دور است و نشان می دهد که باقیمانده زیادی دارد، همانطور که در زیر مشخص شده است:
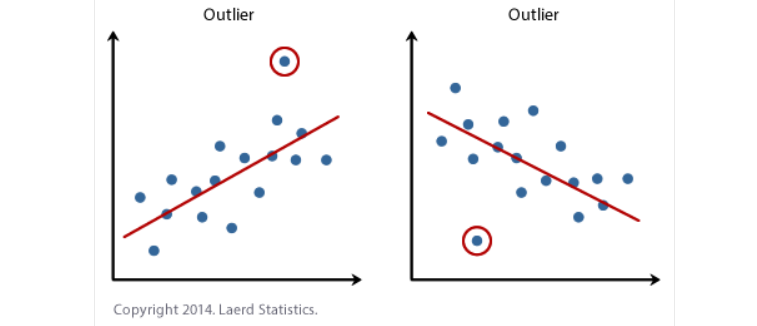
مشکل پرت ها این است که می توانند تأثیر منفی بر تحلیل رگرسیون داشته باشند (به عنوان مثال، تناسب معادله رگرسیون را کاهش دهند) که برای پیش بینی مقدار متغیر وابسته (نتیجه) بر اساس متغیر مستقل (پیش بینی کننده) استفاده می شود. این خروجی را که آمار SPSS تولید می کند تغییر می دهد و دقت پیش بینی نتایج شما را کاهش می دهد. خوشبختانه، هنگام استفاده از آمار SPSS برای اجرای یک رگرسیون خطی روی دادههای خود، میتوانید به راحتی معیارهایی را برای کمک به تشخیص موارد دور از دسترس در نظر بگیرید. در راهنمای رگرسیون خطی پیشرفته ما: (الف) به شما نشان میدهیم که چگونه با استفاده از “تشخیص موردی” که یک فرآیند ساده در هنگام استفاده از آمار SPSS است، نقاط پرت را شناسایی کنید. و (ب) در مورد برخی از گزینه هایی که برای مقابله با موارد پرت دارید بحث کنید.
فرضیه شماره ۵: شما باید از مشاهدات استقلال داشته باشید، که به راحتی می توانید با استفاده از آمار Durbin-Watson، که یک تست ساده برای اجرا با استفاده ازنرم افزار SPSS است، بررسی کنید. ما توضیح خواهیم داد که چگونه نتیجه آزمون دوربین-واتسون را در راهنمای رگرسیون خطی پیشرفته خود تبیین کنیم.
فرضیه شماره ۶: داده های شما باید همسانی را نشان دهند، جایی که واریانس ها در امتداد خط بهترین تناسب مشابه با حرکت شما در طول خط باقی می مانند. در حالی که ما در راهنمای رگرسیون خطی بهبودیافته خود درباره معنای این و چگونگی ارزیابی همسویی بودن دادههایتان توضیح میدهیم، به سه نمودار پراکندگی زیر که سه مثال ساده ارائه میدهند، نگاهی بیندازید: دو مورد از دادههایی که این فرض را ناموفق میدانند (به نام ناهمسانی). و یکی از داده هایی که این فرض را برآورده می کند (به نام homoscedasticity)
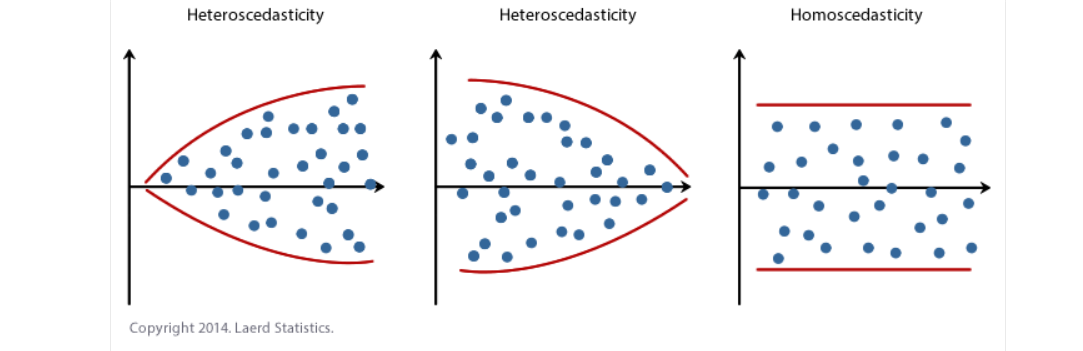
در حالی که اینها به نشان دادن تفاوتها در دادههایی کمک میکنند که با فرض هم جهت بودن مطابقت دارند یا آن را نقض میکنند، دادههای دنیای واقعی میتوانند بسیار آشفتهتر باشند و الگوهای مختلف ناهمگنی را نشان دهند. بنابراین، در راهنمای رگرسیون خطی پیشرفتهمان، توضیح میدهیم: (الف) برخی از مواردی که باید هنگام تفسیر دادههای خود در نظر بگیرید. و (ب) راههای ممکن برای ادامه تحلیل شما در صورتی که دادههای شما با این فرضیه مطابقت نداشته باشند.
فرضیه ۷: در نهایت، باید بررسی کنید که باقیماندهها (خطاهای) خط رگرسیون تقریباً به طور معمول توزیع شدهاند (این اصطلاحات را در راهنمای رگرسیون خطی بهبود یافته توضیح میدهیم). دو روش متداول برای بررسی این فرض شامل استفاده از هیستوگرام (با منحنی نرمال روی هم قرار داده شده) یا نمودار P-P نرمال است. مجدداً، در راهنمای رگرسیون خطی پیشرفتهمان، ما: (الف) به شما نشان میدهیم که چگونه با استفاده از نرم افزار SPSS این فرض را بررسی کنید، چه از یک هیستوگرام (با منحنی نرمال روی هم قرار داده شده) یا P-P Plot معمولی استفاده کنید. (ب) توضیح دهید که چگونه این نمودارها را تفسیر کنید. و (ج) در صورتی که دادههای شما این فرض را برآورده نکنند، راهحلی ممکن ارائه دهید.
با استفاده از نرم افزار SPSS می توانید فرضیات #۳، #۴، #۵، #۶ و #۷ را بررسی کنید. پیش از حرکت به پیش فرض های شماره ۴، ۵، ۶ و ۷ ابتدا باید فرضیات شماره ۳ بررسی شوند. ما پیشنهاد میکنیم فرضیات را به این ترتیب آزمایش کنید زیرا فرضیه های #۳، #۴، #۵، #۶ و #۷ از شما میخواهند که ابتدا رویه رگرسیون خطی را در آمار SPSS اجرا کنید، بنابراین پس از بررسی فرضیه ۱، رسیدگی به آنها آسانتر است. و #۲. فقط به یاد داشته باشید که اگر آزمون های آماری را بر اساس این فرضیه ها به درستی اجرا نکنید، نتایجی که هنگام اجرای رگرسیون خطی به دست می آورید ممکن است معتبر نباشند. به همین دلیل است که ما تعدادی از بخشهای راهنمای رگرسیون خطی بهبودیافته خود را برای کمک به شما در درستی این موضوع اختصاص میدهیم. میتوانید در مورد محتوای بهبود یافته ما به طور کلی در ویژگیهای ما اطلاعات بیشتری کسب کنید: صفحه مرور کلی، یا به طور خاص، یاد بگیرید که چگونه به آزمایش فرضیات در صفحه ویژگیها: فرضیات ما کمک میکنیم.
در بخش رویه، روش آماری SPSS را برای انجام یک رگرسیون خطی با فرض اینکه هیچ فرضی نقض نشده است، نشان میدهیم. ابتدا مثالی را که در این راهنما استفاده شده معرفی می کنیم.
نکته: یک دیگر از نرم افزارهایی که می تواند در رابطه با تحلیل داده ها به شما کمک کند لیزرل است که جهت انجام پروژه lisrel خود نیازمند آن هستید که آموزش کافه پروژه را از ابتدا ملاحظه نمایید لذا جهت مشاهده و آموزش های مرتبط با این نرم افزار لازم است کلمه آموزشlisre l را در بخش جستجو وارد نمایید و اینتر بزنید
نرم افزار SPSS
مثال
یک فروشنده برای یک برند بزرگ خودرو می خواهد تعیین کند که آیا رابطه ای بین درآمد یک فرد و قیمتی که برای یک تخته فرشمی پردازد وجود دارد یا خیر. به این ترتیب، «درآمد» افراد، متغیر مستقل و «قیمت»ی که برای یک تخته فرش می پردازند، متغیر وابسته است. فروشنده می خواهد از این اطلاعات برای تعیین اینکه کدام فرش ها ا را به مشتریان بالقوه در مناطق جدیدی که درآمد متوسط مشخص است، به نمایش بگذارد، استفاده کند.
نحوه سفارش پروژه در سایت کافه پروژه :
اگر پروژه ای دارید که میخواهید آن را برون سپاری کنید کافی است در سایت کافه پروژه ثبت نام کنید و پروژه خود را ثبت نمایید.پروژه شما هر چه که باشد حتما مجری برای آن وجود دارد.جهت ثبت نام و ثبت سفارش پروژه خود برروی دکمه زیر کلیک نمایید.

){kind=link}
بدون دیدگاه